Kotisivun teko » HTML-kieli
HTML-kieli
Kotisivut tehdään HTML-kielellä
WWW:hen laitettavat kotisivut tehdään siis käyttäen HTML-kieltä. Mutta mikä HTML-kieli on? HTML on lyhenne sanoista HyperText Markup Language. HTML on siis www-sivujen esittämiseen kehitetty sivunkuvauskieli. HTML ei ole mikään ohjelmointikieli kuten esim. PHP, Java tai C-kieli. HTML-kielellä ei voi siis tehdä tietokoneohjelmia vaan se on tarkoitettu www-sivujen rakenteen esittämiseen.
WWW:ssä voi toki julkaista muunkin muotoisia tiedostoja kuin HTML-kielellä kirjoitettuja dokumentteja. WWW-palvelimelle voi laittaa normaaleja tekstidokumentteja (.txt), Wordin dokumentteja (.doc), mp3-musiikkia jne. Aikoinaan kuitenkin sovittiin, että olisi suositeltavaa esittää tekstidokumentit WWW:ssä HTML-muodossa.
On huomattavasti helpompaa, että on yksi standardinmukainen tapa esittää tietoa kuin että kaikki esittäisivät tiedon kuka missäkin muodossa. Kaikilla kun ei esim. ole välttämättä Microsoft Wordiä. Mutta HTML-kielellä kirjoitettuja www-sivuja lukeva Internet-selain on lähes jokaisessa tietokoneessa.
Kerrataan vielä Johdanto-osassa näytetty esimerkki, jossa tarkasteltiin dokumentin esittämistä pelkkänä tekstinä ja HTML-muodossa.
HTML-muotoinen dokumentti oli siis huomattavasti mukavampi luettava. Siihen saa myös upotettua tekstin sekaan havainnollistavia kuvia ja tekstistä pääsi helposti lukemaan koko tutkielman yhtä linkkiä klikkaamalla.
Jos avaat edellä mainitun tekstimuotoisen ja HTML-muotoisen dokumentit ja katsot nettiselaimesi avulla sivujen lähdekoodia (Näytä...Lähdekoodi, View...Source), näet että ne ovat melko samanlaisia. HTML-muotoisessa dokumentissa on vain sivun alussa outoja määritteitä ja tekstin seassa on joitain outoja hakasia. Nämä "hakaset" ovat ns. tägejä, joista HTML-kieli koostuu. Sivun alussa olevat määreet taas kuuluvat HTML-kielen määrittelyihin. Kyseessä on itse asiassa XHTML-dokumentti. XHTML-kieli on HTML-kielen seuraaja ja siitä lisää tuonnempana.
HTML-kieli koostuu tägeistä
HTML-kieli on hyvin yksinkertainen verrattuna ohjelmointikieliin. Oikeastaan niitä ei kannattaisi edes rinnastaa, koska kyseessä on aivan eri asiat. HTML-kieli koostuu ns. tägeistä, joiden avulla kuvataan sivun rakennetta. Näillä tägeillä merkitään tekstisisällön sekaan esimerkiksi, mitkä kohdat tekstistä näytetään lihavoidulla, mihin kohtaan sivua tulee kuva, mihin taulukko ja mitkä tekstinpätkät toimivat linkkeinä jne.
Tägillä on lähes aina alkutägi, joka on muotoa <tägi> ja lopputägi, joka on muotoa </tägi>. Lisäksi alkutägin sisällä voi olla jotain erikoismääreitä. Esimerkiksi taulukon voi luoda www-sivulle <table>-tägillä. Taulukon reunojen paksuuden voi määrätä lisäämällä table-tägiin määre border tyyliin <table border="3">, joka tarkoittaisi, että taulukkomme reunaviivan paksuus on 3 pikseliä.
Tägejä on useita erilaisia ja niillä määritellään eri asioita. Esimerkiksi teksti, joka on ympäröity tyyliin <strong>tässä on tekstiä</strong>, näyttää selaimessa seuraavalta: tässä on tekstiä. Kyseinen tägi siis paksuntaa sen kohdan tekstistä, joka on tägin alkutägin ja lopputägin välissä.
On myös tägejä, joilla ei ole lopputägiä. Esimerkiksi rivinvaihto
tehdään pelkästään tägillä <br>. Kyseisellä tägillä ei siis ole lopputägiä.
XHTML-kielessä lopputägittömät tägit pitää lopettaa
alkutägissä tyyliin <br />. Eli lisätään kauttaviiva alkutägin loppuun.
Kaikki HTML-tägit löytyvät esim. mainiolta
W3Schools-sivustolta.
HTML-dokumentti alkaa aina dokumenttityypillä, jossa kerrotaan, mitä kieltä dokumentissa käytetään (yleensä HTML 4.01). Tämän jälkeen tulee aina html-tägi, joka ympäröi koko dokumentin sisällön. Html-tägin sisältö jakaantuu kahteen osaan: head- ja body-osiin. Head-osassa kerrotaan dokumentin otsikko title-tägin sisällä. Head-osassa voi myös olla kaikenlaisia meta-määreitä ja linkkejä CSS- ja JavaScript-tiedostoihin. Body -osa on varsinainen dokumentin sisältö, joka näkyy tietokoneen ruudulla, kun sivua selaa nettiselaimella. Body-tägien sisään siis kirjoitetaan varsinainen dokumentin sisältö käyttäen HTML-kieltä.
Alla on esimerkki HTML 4.01 -kielellä kirjoitetusta dokumentista. Voit myös katsoa, miltä sivu näyttää nettiselaimessa.
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html> <head> <title>MVnet :: Esimerkkisivu HTML-koodin käytöstä</title> </head> <body> <!--Varsinainen tekstisisältö alkaa --> <p>Tämä sivu on siis <strong>esimerkkinä HTML-koodin käytöstä</strong>. HTML-koodin avulla saa tekstidokumentista paljon elävämmän. Käyttämällä lisäksi CSS-tyyliohjeita, saat määriteltyä sivun esitysasun haluamaksesi ja teet tyylikkäitä ja toimia sivuja.</p> <p>HTML:n avulla dokumenttiin voi myös sisällyttää kuvia. Kuva lisätään img-tägillä. Seuraavassa on lisätty MVnetin logo img-tägin avulla:</p> <p><img src="kuvat/layout/mvnetlogo.png" alt="Esimerkkikuva" /></p> <p>HTML:n avulla voi myös tehdä linkkejä. Seuraavassa on linkki tämän MVnetin <a href="index.php?osio=Kotisivun_teko &sivu=HTML-kieli#linkit"> Kotisivun teko -osion HTML-kieli-sivulle</a>.</p> </body> </html>
HTML-dokumentin alussa on siis dokumenttityypin määrittely, jossa kerrotaan, mitä kieltä dokumentissa on käytetty. Esimerkissä kieleksi on valittu HTML 4.01. Dokumenttityypin jälkeen tulevat pakolliset html- ja head-tägit. Head-tägin sisällä on siis pakollinen title-tägi, jossa on kerrottu dokumentin otsikko, joka näkyy nettiselaimessa ikkunan otsikkona. Head-tägin jälkeen on pakollinen body-tägin alkutägi, jonka jälkeen tulee varsinainen dokumentin sisältö.
Html-koodissa oleva <!--Varsinainen tekstisisältö alkaa --> -kohta on kommentti, joka näkyy vain html-koodissa. Se ei näy itse sivussa, kun sitä katselee normaalisti nettiselaimella. Kommentit helpottavat hahmottamaan html-koodia, joten niitä kannattaa käyttää.
Body-tägien sisällä on neljä kappaletta tekstiä. Kappaleet alkavat aina <p>-tägillä ja loppuvat </p>-tägiin. Kappalejako helpottaa huomattavasti tekstin lukemista. Ensimmäisessä kappaleessa on käytetty strong-tägiä, joka paksuntaa tägin sisältämän tekstin. Kolmannessa kappaleessa dokumenttiin on lisätty kuva img-tägillä. Kuvan osoite, joka sivuun linkitetään, kerrotaan img-tägin src-attribuutissa. Alt-attribuutti, on pakollinen attribuutti kuville, jossa pitää kertoa lyhyesti, mistä kuva kertoo.
Viimeisessä eli neljännessä kappaleeseen on lisätty linkki tähän sivuun, jota parhaillaan luet ja tarkemmin vielä nimettyyn kohtaan linkit. HTML-dokumenttiin kun voi tehdä ns. ankkureita eli määrittää johonkin kohtaan sivua ankkuri, johon voi sitten viitata linkillä tyyliin Siirry toiseen kohtaan sivua. Tätä linkkiä klikkaamalla pääsee siis siirtymään sivulla tiettyyn nimettyyn kohtaan.
HTML-kielen linkit
HTML-kielessä linkki määritellään muodossa <a href="http://www.mvnet.fi/">Linkki</a>. Kursivoidun tekstin tilalle tulee siis linkin URL-osoite ja paksunnettu teksti on se, joka näkyy linkkinä selaimessa. HTML-kielessä linkin URL-osoite voi olla joko absoluuttinen tai suhteellinen. Suhteellista osoitetta käytetään, kun linkitetään omia sivuja ja absoluuttista osoitetta käytetään, kun linkitetään muiden tekemiä sivuja. Absoluuttisen linkin osoite alkaa aina tyyliin http://. Relatiivisessa linkissä taas ei tarvita tuota alku-osaa, koska jos linkitettävä tiedosto sijaitsee samassa kansiossa kuin sivu, johon linkki tulee, tarvitsee linkkiin laittaa vain linkitettävän tiedoston nimi.
Jos esimerkiksi sivulla, jonka osoite on http://www.kotisivusi.fi/etusivu.html haluttaisiin tehdä linkki sivuun http://www.kotisivusi.fi/palaute.html, riittäisi linkin osoitteeksi laittaa absoluuttisen URL-osoitteen sijasta lyhemmin palaute.html. Koska palaute.html sijaitsee suhteessa etusivu.html-tiedostoon samassa kansiossa, riittää linkin osoitteeksi palaute.html.
Samassa hakemistossa olevat dokumentit voivat siis viitata toisiinsa yksinkertaisesti tiedostonimillä. Tämän lisäksi dokumentista voi olla viittauksia hakemiston alihakemistoissa oleviin tiedostoihin. Suhteellisen osoitteen alkuun laitetaan tällöin alihakemiston nimi, jota seuraa vinoviiva ja tiedoston nimi. Esimerkiksi sivusta, jonka osoite on http://www.kotisivusi.fi/etusivu.html voi viitata sivuun, jonka osoite on http://www.kotisivusi.fi/galleria/kuvat.html lyhyesti osoitteella galleria/kuvat.html.
Suhteellinen osoite voi viitata myös hakemistopuussa ylöspäin. Tällöin suhteellinen URL-osoite alkaa osalla ../. Näitä osia voi olla monta peräkkäin. Esimerkiksi sivulta, joka on osoitteessa http://www.kotisivusi.fi/galleria/omat/tietoa.html voi viitata sivuun http://www.kotisivusi.fi/etusivu.html lyhemmin käyttämällä suhteellista osoitetta ../../etusivu.html.
Suhteellisilla URL-osoitteilla on useita etuja. Ne ovat ensinnäkin lyhyempiä kirjoittaa ja niitä käyttämällä www-sivuston voi helposti siirtää palvelimelta toiselle. Jos sivun domain-osoite vaihtuu, ei linkkejä tarvitse muuttaa, jos ne ovat niissä on kaikissa suhteellisia osoitteita. Käyttämällä suhteellisia osoitteita voi sivustosta myös tehdä imuroitavan version, jolloin kävijä voi ladata koko sivuston omalle koneelle ja selata sivuja ilman nettiyhteyttäkin. Käytä siis suhteellisia osoitteita aina kun on mahdollista. Lisätietoa linkeistä löytyy Jukka Korpelan mainiosta Web-julkaisemisen oppaasta osasta Linkkejä peliin.
HTML-kielen eri versiot
On sovittu, että HTML-dokumentin alussa pitää olla aina tietty tekstinpätkä, josta dokumentissa käytetty kieli tunnistetaan. Tätä HTML-dokumentin alussa olevaa tekstiä kutsutaan nimellä dokumenttityyppi (engl. doctype). HTML-kielestä kun on eri versioita, jotka poikkeavat hieman toisistaan. HTML-kielen uusin versio on HTML 4.01. Vanhempia versioita on mm. HTML 4.0, HTML 3.2 ja HTML 2.0. Näitä vanhoja versioita ei kannattaisi enää käyttää. Näin suosittelee WWW:n standardeja ja suosituksia johtava W3C (World Wide Web Consortium). Dokumenttityyppi riippuu siis dokumentissa käytetystä HTML-kielen versiosta. Esimerkiksi HTML 3.2 -kielen mukaisesti kirjoitetun dokumentin alussa pitää olla aina seuraava dokumenttityypin määrittely:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
Koska vanhoja HTML-kielten versioita ei enää suositella käytettävän, ovat lähes kaikki nettisivut HTML 4.01 -kielen mukaisia. Jotta asiat eivät olisi aivan yksinkertaisia, on HTML 4.01-kielestäkin on vielä muutama eri versio: Strict, Transitional ja Frameset.
Transitional - ja Strict-kielten ero on lähinnä siinä, että Transitional-kielessä sallitaan ne tägit, jotka ovat vanhentuneet ja joita ei pitäisi enää käyttää. HTML-kielikin kun kehittyy koko ajan. Esimerkiksi font-tägiä, jolla voisi määrittää tekstin fontin koon ja värin, ei sallita HTML 4.01 Strict-kielessä, mutta HTML 4.01 Transitional-kielessä se on sallittu. Font-tägin sijasta suositellaan käytettävän CSS-tyylejä fontin koon ja värin määrittämiseen. Transitional-kieli on siis vähän löyhempi kieli. Strict-kielen käyttö on suositeltavaa, koska vanhentuneita tägejä ei välttämättä tueta enää tulevaisuudessa, jolloin saattaa tulla ongelmia sivun näyttämisessä nettiselaimissa. HTML 4.01 Frameset on käytännössä sama kuin Transitional, mutta tätä kieltä pitää käyttää, jos sivuilla käytetään kehyksiä eli frameja.
Alla on esitetty vielä, mikä dokumenttityypin määrittely pitää laittaa dokumentin alkuun. Dokumenttityyppi riippuu siis käytetystä HTML-kielen versiosta. Suositeltavaa on siis käyttää näistä HTML 4.01 Strict-kieltä. Alla siis vastaavat määrittelyt:
HTML 4.01 Strict:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
HTML 4.01 Transitional:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
HTML 4.01 Frameset:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd">
Dokumenttityypit ovat tärkeitä koodin validoinnin kannalta. Validoinnilla tarkoitetaan siis sitä, että sivun HTML-koodi tarkastetaan jollain validaattorilla, joka katsoo, onko dokumentti sen dokumenttityypin määrittelyssä esitetyn HTML-kielen mukaista. Jos dokumenttityypissä on väitetty, että dokumentti on HTML 4.01 Strict -kielen mukaista, mutta dokumentti onkin kirjoitettu käyttäen HTML 4.01 Transitional -kieltä, voi validaattori herjata tästä ja ilmoittaa, että dokumentin HTML-koodi ei ole validia. Validi koodi on tärkeää mm. siksi, että tällöin sivu näkyy varmemmin oikein nettiselaimilla. Dokumenttityypin perusteella nettiselain tunnistaa, mitä kieltä dokumentissa on käytetty ja osaa näyttää sivun tämän perusteella oikein.
XHTML - paranneltu versio HTML:stä
Suurin osa nettisivuista on siis tehty käyttäen HTML 4.01 -kieltä. Nykyään on kuitenkin yleistymässä HTML-kielen seuraaja eli XHTML-kieli, jolla MVnetin kaikki sivut on myös kirjoitettu. XHTML-kieli on käytännössä lähes sama kuin HTML 4.01. Kummallakin saa esitettyä samat asiat, mutta XHTML-kielessä on tiukemmat säännöt.
Tärkein syy XHTML:n kehittämiseen lienee se, että XHTML sopii HTML:ää paremmin myös muihin medioihin kuin perinteisiin tietokoneisiin. Tällaisia ovat esim. matkapuhelimet ja muut mobiililaitteet, joilla pääsee myös nykyään nettiin. Mobiililaiteiden tehot ovat kuitenkin tietokonetta rajallisemmat ja HTML:n rönsyilevä syntaksi on hieman raskasta pureksittavaa mobiililaitteille. Siksi XHTML-kielelle oli siis tarvetta.
Toinen merkittävä syy XHTML-kielen käyttöönottoon on sen XML-pohjainen rakenteellisuus, joka estää tehokkaasti virheet sivun merkkauksessa ja tekee XHTML-dokumentista helposti validoitavan. HTML-kielessä on sallittua jättää joidenkin tägien lopputägit pois. Esimerkiksi kappaleen loppua ei tarvitse merkitä HTML-kielessä </p>-tägillä, jos seuraava kappale alkaa heti edellisen kappaleen jälkeen. XHTML-kielessä taas kaikki tägit on pakko sulkea ja vielä oikeassa järjestyksessä sen XML-pohjaisuuden takia. HTML-kielessä tägit pitää myös sulkea oikeassa järjestyksessä, mutta HTML-kieli on siis paljon löyhempi lopputägien suhteen.
Esimerkiksi seuraavanlainen tekstipätkä on HTML-kielen syntaksin mukaista ja menee läpi validaattorista, jos käytetään HTML-kieltä. XHTML-kieltä käytettäessä validaattori taasen antaa virheilmoituksen, koska kyseinen tekstipätkä ei ole XHTML-kielen mukaista.
<p>Ensimmäinen kappale <p>Toinen kappale
Yllä esitetyssä virheellisesti muotoillussa tekstissä siis p-tägit pitäisi lopettaa </p>-tägillä seuraavasti:
<p>Ensimmäinen kappale</p> <p>Toinen kappale</p>
XHTML-kielen ensimmäinen versio XHTML 1.0 on käytännössä sama kuin HTML 4.01. Erona on lähinnä XHTML:n rajoitukset siinä, että tägit täytyy aina kirjoittaa pienillä kirjaimilla, kun HTML:ssä ne voi kirjoittaa pienillä tai isoilla kirjaimilla. Lisäksi XHTML-kielessä kaikki tägit pitää siis sulkea ja lopputägittömät tägit pitää sulkea alkutägissä tyyliin <br /> kun HTML-kielessä tämän saa kirjoittaa <br>.
XHTML 1.0 -kielestä on myös HTML 4.01 -kielen tapaan kolme eri versiota: Strict, Transitional, ja Frameset, jotka eroavat toisistaan lähes samalla lailla kuin HTML-kielen vastaavat. Näin on, koska kyseessä on siis käytännössä lähes sama kieli. XHTML-dokumentin alussa pitää HTML-dokumentin tapaan myös ilmoittaa dokumenttityyppi, joka riippuu käytetystä XHTML-kielen versiosta.
Alla on esitetty vielä, mikä dokumenttityypin määrittely pitää laittaa dokumentin alkuun. Dokumenttityyppi riippuu siis käytetystä XHTML-kielen versiosta. Suositeltavaa on käyttää näistä XHTML 1.0 Strict-kieltä. Alla siis vastaavat määrittelyt:
XHTML 1.0 Strict:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
XHTML 1.0 Transitional:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
XHTML 1.0 Frameset:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
XHTML-kielestä on tullut myös XHTML 1.1 -versio, joka on käytännössä sama kuin XHTML 1.0 Strict pienillä muutoksilla. XHTML-kielestä voi lukea lisää W3C:n XHTML-spesifikaatiosta, joka on tosin englanninkielinen.
XML-kielestä lyhyesti
XHTML on siis HTML-kielen versio, joka on kirjoitettu XML-kielellä. XML-kieli taas on merkkauskieli, jolla tiedon merkitys on kuvattavissa tiedon seassa. XML-kielet kuvaavat dokumentin loogista rakennetta, eivät niiden esittämistä. XML-kielellä siis kuvataan vain data, ei ulkoasua. Ulkoasu voidaan kuvata käyttämällä esimerkiksi CSS-tyyliohjeita.
Otetaan esimerkiksi klassinen esimerkki ruokareseptin kirjoittamisesta XML-kielellä, joka on esitetty alla. Esityksessä ei siis mitenkään oteta kantaa siihen, miten tiedot esitetään (ei ole esimerkiksi kerrottu fonttien kokoa, väriä tms.). Esityksessä on vain yksinkertaisesti kuvattu esitetyn tiedon merkitys XML-tägeillä.
<?xml version="1.0" encoding="iso-8859-1"?> <resepti nimi="patonki" aika_uunissa="1 tunti"> <otsikko>Patongin teko-ohje</otsikko> <tarvittavat_aineet> <aine määrä="5" yksikkö="desilitra">Vehnäjauhoja</aine> <aine määrä="0.5" yksikkö="paketti">Hiiva</aine> <aine määrä="2" yksikkö="desilitra">Vesi</aine> <aine määrä="1" yksikkö="teelusikka">Suola</aine> </tarvittavat_aineet> <valmistusohje> <vaihe>Sekoita kaikki aineet kulhoon keskenään.</vaihe> <vaihe>Peitä kulho liinalla ja anna kohota tunnin.</vaihe> <vaihe>Leivo taikinasta 4 patonkia pellille.</vaihe> <vaihe>Laita pelti 225-asteiseen uuniin tunniksi.</vaihe> </valmistusohje> </resepti>
Jos yllä esitetyn XML-kielellä kirjoitetun dokumentin avaa nettiselaimeen, ei selaimessa näy kuin tekstiä peräperää, josta ei oikein saa selkoa. Käyttämällä CSS-tyylitiedostoa, voisi selaimelle kertoa, miten dokumentin halutaan näkyvän.
XHTML-kieli on siis hyvin samankaltainen kuin edellä esitetty esimerkki XML-kielestä. XHTML-kielessä vaan ei saa käyttää tägien niminä ihan mitä haluaa, vaan ne on ennalta määrätty (esim. title, h1, strong, jne...). XHTML-kielikin on tarkoitettu dokumentin rakenteen kuvaamiseen ja tämä kannattaa pitää mielessä XHTML-dokumentteja kirjoitettaessa. Pyri siis siihen, että otat dokumentissa mahdollisimman vähän kantaa ulkoasuun. Ulkoasu on järkevintä määritellä CSS-tyyliohjeilla.
Validi koodi tärkeää
Kun HTML-koodi on kirjoitettu oikein HTML-kielen sääntöjen mukaisesti, sanotaan, että kirjoitetun dokumentin koodi on validia. Validi koodi on tärkeää, jotta sivut näkyisivät oikein jokaisella nettiselaimella. Jos koodi ei ole validia, voi joku selain näyttää sivun aivan päin honkia. Nettiselaimet kun tulkitsevat sivua HTML-kielen sääntöjen mukaan. Jos säännöistä poiketaan, voi jokainen selain tulkita koodin omalla tavallaan. Lisäksi hakukoneet, kuten Google, eivät välttämättä osaa indeksoida sivujasi täysin oikein, jos sivujen HTML-koodi ei ole validia.

Acid2-testi Opera 9.0:llä.

Acid2-testi Firefox 1.5:llä.
Dokumentin HTML-koodin voi validoida esimerkiksi W3C:n validaattorilla, jolla voi validoida www-sivuja URL-osoitteesta, omalta koneelta kokonaisen HTML-dokumentin tai kopioimalla validaattoriin sivun lähdekoodin. Jos sivun HTML-koodi ei ole validia, antaa validaattori selvityksen siitä, missä kohtaa dokumentissa HTML-kieli poikkeaa säännöistä. Validaattorin ilmoitusten perusteella on melko helppo korjata virheelliset kohdat sivusta. Validoinnin voi suorittaa helposti myös Firefoxilla HTML Validator -lisäosan avulla, joka helpottaa ja nopeuttaa sivun HTML-koodin validointia.
HTML-koodin lisäksi myös CSS-koodin olisi hyvä olla validia. CSS-koodin kanssa on sama juttu - jos koodi ei ole validia, eivät selaimet välttämättä tulkitse koodia ollenkaan tai sitten miten sattuu. CSS-koodin validointiin taas voi käyttää W3C:n CSS-validaattoria. Ennen CSS-koodin validoimista, pitäisi kuitenkin validoida HTML-koodi. Jos HTML-koodi ei ole validia, ei validista CSS-koodista ole paljoa iloa.
Vaikka dokumentin koodi olisikin validia, ei se siltikään tarkoita välttämättä sitä, että sivu näkyisi halutulla tavalla kaikilla valtaselaimilla. Selainten tuki HTML- ja CSS-standardeille on vaihtelevaa. Esim. Opera-selain noudattelee standardeja lähes orjallisesti, mutta Internet Explorerin tuki standardeille on vähän mitä sattuu.
Validia koodia sisältävä sivu voikin näkyä täysin halutusti Operalla ja Firefoxilla, mutta Internet Explorer saattaakin näyttää sen aivan päin seiniä. Tällöin täytyy vain yrittää muokata koodia niin, että sivu näkyisi mahdollisimman siedettävänä myös IE:llä. Missään tapauksessa ei kannata hylätä IE:n käyttäjiä. Sivut ovat huonosti suunniteltu, jos ne eivät toimi IE:ssä. Reilusti yli 50 % nettisurffailijoista kuitenkin käyttää yhä IE:tä. Jos sivusi ovat yhtä mössöä IE:llä katsottuna, menetät huomattavasti kävijöitä. Vaikka kotisivun tekijällä palaakin varmasti useamman kerran hermot Internet Explorerin kanssa, on sen kanssa vain elettävä.
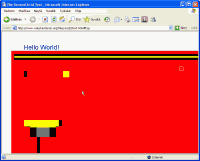
Acid2-testi Internet Explorer 6:lla. Näetkö hymiötä?
Voit itsekin kokeilla, kuinka erilaisesti selaimet tulkitsevat HTML- ja CSS-kielten standardeja. Tätä tarkoitusta varten on kehitetty ns. Acid2-testi, joka testaa, kuinka hyvin selain noudattaa W3C:n HTML- ja CSS-standardeja. Testissä pitäisi selaimen ruudulle piirtyä kuva, joka esittää hymiötä. Kuten oikealla esitetyistä kuvista huomaa, on esimerkiksi Internet Explorer 6 -selaimen tuki standardeille todella heikkoa. Kyseisestä sivusta ei tosiaankaan saisi selville, että siinä pitäisi olla hymiö. Opera 9 -selain taas noudattelee standardeja lähes orjallisesti ja onkin yksi niistä harvoista selaimista, joka läpäisee Acid2-testin puhtaan arvosanoin. Firefoxin piirtämästä kuvasta taas saa vielä jotenkin selvän, että kyseessä pitäisi olla hymiö, mutta senkin piirtämässä kuvassa on paljon virheitä.
Vaikka selain läpäisisikin Acid2-testin, ei se kuitenkaan tarkoita, että selain olisi täydellinen. Acid2-testi kun ei testaa kaikkea mahdollista HTML- ja CSS-kielistä. Testi antaa kuitenkin hyvän kuvan siitä, kuinka todennäköisesti validia koodia sisältävä sivu näkyy selaimessa kuten on haluttu.
Lisätietoa HTML-kielestä
Yllä esitetty johdanto HTML-kieleen oli varsin suppea esitys siitä, mitä kaikkea HTML-kielellä voi tehdä. Lisätietoa HTML-kielestä löytyy mm. seuraavista suomenkielisistä artikkeleista. Lisää linkkejä oppaisiin löytyy sivulta Linkkejä kotisivun tekijälle.
- XHTML- ja HTML-perusteet (Tietoa suomeksi HTML:stä ja XHTML:stä )
- Sivut.web - HTML (Perusopas HTML-kielen alkeisiin)
- Web-julkaisemisen opas - Rakennetta mukaan (Jukka Korpelan artikkeli HTML-kielestä)
- HTML-elementit (Tietoa HTML-elementeistä suomeksi)
"En ymmärrä HTML-kielestä mitään!"
Jos et ymmärtänyt yllä olevasta HTML-koodin esittelystä kaikkea, se ei oikeastaan haittaa. Kotisivuja voi tehdä vaikka ei ymmärtäisi HTML-koodin käytöstä juuri mitään, kunhan vaan käyttää kunnon kotisivunteko-ohjelmaa. Kotisivujen tekoa varten on tehty ns. WYSIWYG-editoreja (What You See Is What You Get - eli se mitä näet, on se mitä saat). WYSIWYG-editorilla voit tehdä www-sivua kuin Wordin dokumenttia ikään. Sinun ei tarvitse tietää HTML-koodista juuri mitään. Valitset vain ohjelman valikosta esimerkiksi taulukon ja editori lisää sen sivuun. Sitten laitat sisältöä taulukon soluihin ja muuttelet tekstin väriä ja kokoa klikkailemalla erilaisia painikkeita jne. Editori huolehtii HTML-koodin kirjoittamisesta. Voit muokata sivua sellaisena kuin se tulee (toivottavasti) selaimessa näkymään.
Kuitenkin html-koodin käytön opettelemisesta on hyötyäkin. (X)HTML-kielen ja CSS-koodin avulla voi sivuista tehdä paljon hienompia kuin jollain WYSIWYG-editorilla. WYSIWYG-editorit kun eivät aina tuota validia koodia, jolloin sivu voi näkyä hyvin eri lailla eri selaimissa. Ainakin perusjutut html-koodin käytöstä olisi hyvä opetella, jotta ymmärtää, mitä on tekemässä.
Merkistöt ja entiteetit
HTML-dokumenttien teossa saattaa ennen pitkään törmätä merkistöihin (engl. character encoding, character set). Merkistöt ovat usein tavalliselle käyttäjälle näkymätön asia, jota voi olla hieman vaikea käsittää. Merkistöjä ei ole pakko ymmärtää, koska jos kaikki toimii kuten pitääkin, ei niillä tarvitse vaivata päätään. Mutta merkistöihin törmää melko varmasti jossain vaiheessa, jos perehtyy www-sivujen tekoon tarkemmin. Tässä esitetyt asiat vaativat hieman ymmärrystä tiedostoista, HTML-kielestä ja www-sivujen toiminnasta yleisesti.
Merkistö on sopimus, jossa määritellään, mitkä eri bittiyhdistelmät tulkitaan miksikin merkiksi. Tietokone kun käsittelee merkit aina bittijonoina (ykkösistä ja nollista koostuva numerojono). Kuvitteellinen esimerkki voisi olla esim. 6-bittinen merkistö, jossa bittijono 000000 vastaisi merkkiä a, 000001 vastaisi merkkiä b ja 000010 merkkiä c jne. Yksi ensimmäisiä merkistöjä oli 7 bitistä koostuva ASCII-merkistö (merkkejä vastaavia bittijonoja ei ole oleellista tietää). 7 bittiä ei kuitenkaan riitä esittämään kuin 128 merkkiä, joka ei ole tarpeeksi. Yhdysvalloissa kehitetty ASCII soveltuu melko hyvin amerikanenglannin kirjoittamiseen, mutta mm. suomen ja ruotsin kielissä tarvittavia ä- ja ö-kirjaimia ei siinä ole määritelty. Tämän takia merkistöistä täytyi tehdä useita eri versioita eri maiden tarpeita varten, joissa osa merkistön merkeistä oli korvattu toisilla.
Myöhemmin luotiin ISO 8859 -standardi, joka määrittelee useita 8-bittisiä merkistöjä, joissa merkkien määrä on 256. Tämäkään ei riitä kaikkien kielten tarpeisiin, joten taas piti luoda eri alueille omat versiot merkistöstä, joissa samat bittijonot vastasivat osittain eri merkkejä. Merkistöjen eroista johtuu se, että katseltaessa www-sivua, joka on tallennettu eri merkistöllä kuin millä selain sen tulkitsee, osa merkeistä korvautuu toisilla. Kuvitteellinen esimerkki voisi olla esim. että nettisivu on kirjoitettu merkistöllä, jossa kirjain ä vastaa bittijonoa 001010, mutta selain tulkitseekin sivua jostain syystä toisella merkistöllä, jossa bittijonoa 001010 vastaakin merkintä ¥. Näin selain näyttää ä-kirjainten paikalla aivan muun merkin kuin oli tarkoitus, jolloin tekstistä tulee sekavaa.
Merkistöjä on olemassa lukemattomia erilaisia, koska yksikään merkistö ei riitä esittämään kaikkien maailman kielten eri merkkejä. Esim. japanilaisilla on käytössä oma merkistönsä SHIFT_JIS, joka sisältää japanin kielen merkkejä. Venäläisiä varten taas on ISO 8859-5, joka sisältää esim. venäjän kielessä käytetyt kyrilliset aakkoset. Eurooppalaisia varten taas on ISO 8859-1 (tunnetaan myös nimellä Latin 1), joka sisältää useimmat eurooppalaisten kielten sisältämät merkit (kuten kirjaimet ä, ö, å ja ß, mutta ei esim. kirjainta Š, jota näkee käytettävän joskus myös suomen lainasanoissa). Näiden standardoitujen merkistöjen lisäksi on vielä useita ohjelmistokohtaisia merkistöjä, joista tunnetuin on Windows-käyttöjärjestelmissä käytetty Windows-1252 (käytetään joskus nimeä ANSI). Tämä merkistö on itse asiassa laajennus merkistöön ISO 8859-1 (muuten sama, mutta lisää mm. merkit € ja Š). Näiden lisäksi on kehitetty Unicode-merkistö, jonka avulla voidaan esittää noin 100 000 eri merkkiä. Unicode-merkistöistä käytetyin on UTF-8, joka on hyvin yhteensopiva vanhan ASCII-merkistön kanssa. WWW-sivuilla yleisimmin käytetyt merkistöt ovat ISO 8859-1 ja UTF-8. Ei kannata pelästyä merkistöjen outoja nimiä, vaikka ne ehkä hieman vaikeuttavat asian hahmottamista. Nimet ovat vain sopimuksia ja sillä siisti. Paljon lisää tietoa eri merkistöistä löytyy esim. Wikipediasta

Osa sivua, joka on tallennettu merkistöllä ISO 8859-1 ja selain tulkitsee samalla merkistöllä.

Sama sivu, mutta selain tulkitsee sivun virheellisesti käyttäen merkistöä ISO 8859-5

Sama sivu, mutta selain tulkitsee sivun virheellisesti käyttäen merkistöä UTF-8

Sama sivu, mutta nyt tallennettuna merkistöllä UTF-8 ja selain tulkitsee sitä virheellisesti merkistöllä ISO 8859-1.
Tiedostoa varten täytyy aina valita jokin merkistö, jolla se tallennetaan. Sama pätee myös HTML-sivuihin, koska nekin ovat tiedostoja. Kun selain lukee www-sivua, pitää sen tietää, mitä merkistöä sivussa on käytetty, jotta se osaisi näyttää kaikki merkit oikein. Käytetty merkistö ei kuitenkaan aina käy ilmi itse tiedostosta. Jos sivu on tallennettu käyttäen esim. merkistöä UTF-8, mutta selaimelle kerrotaankin, että sen pitäisi tulkita sivu merkistöllä ISO 8859-1, näkyvät esim. ääkköset aivan väärin (kts. kuvat oikealla). Tämä pätee myös toisinpäin: jos sivu on tallennettu käyttäen merkistöä ISO 8859-1, mutta selaimelle kerrotaan, että sen pitäisi käyttää merkistöä UTF-8, ollaan taas vaikeuksissa. Esim. englannin kielen aakkoset näkyvät kyllä oikein, koska molemmissa merkistöissä niitä vastaa sama bittijono, mutta ääkkösten kanssa asia onkin toisin.
Joskus saattaa törmätä virheelliseen käsitykseen, että kaikki erikoismerkit kuten ääkköset pitäisi www-sivuissa muuttaa ns. entiteeteiksi (eli esim. kirjain ä muutettaisiin muotoon ä ja ö muotoon ö), mutta tämä ei ole välttämätöntä. Tällöin ääkköset kyllä näkyvät yleensä oikein, vaikka selain käyttäisikin väärää merkistöä sivun tulkitsemiseen, koska esim. merkinnän ä kaikki merkit vastaavat samoja bittijonoja UTF-8 ja ISO 8859-1 -merkistöissä. Selain vain sitten tulkitsee kyseisen entiteetti-merkinnän ä-kirjaimeksi (entiteetit eivät siis itse asiassa ole osa merkistöjä vaan ne kuuluvat HTML-kieleen). Asian huono puoli on se, että jos ääkköset muuttaa entiteeteiksi, on sivun muokkaaminen tekstieditorissa hyvin epämukavaa, koska sanoja on vaikea hahmottaa (esim. sanan tässä paikalla lukisi tässä) HTML-kielen kaikki entiteetit löytyvät esim. Jukka Korpelan sivulta Entiteetit HTML:ssä. Jotkut merkinnät on HTML:ssä pakko korvata entiteeteillä (kuten esim. &, <, >), mutta tätä ei ole pakko tehdä ääkkösille. Tästä lisää sivulla Merkillisyyksiä: merkit ja niiden koodit.
Jos HTML-sivu on kirjoitettu käyttäen esim. merkistöä ISO 8859-1 tai UTF-8, voi ääkköset jättää sivulle aivan normaalisti eikä niitä tarvitse muuttaa entiteeteiksi. Erikoismerkkejä voi käyttää melko vapaasti, kunhan vain selaimelle kerrotaan oikein se merkistö, millä sivu pitää tulkita. Tietysti pitää ottaa myös huomioon, että osaa merkkejä ei voi käyttää kaikissa merkistöissä - tästä esimerkkinä esim. euro-merkki (€), jota ei ole merkistöissä ISO 8859-1, mutta se löytyy Windows-1252:sta. Jos kyseisen euro-merkin laittaisi sivulle ja kertoisi selaimelle, että sivu pitää tulkita ISO 8859-1 -merkistöllä, saattaisi merkin tilalla näkyä jokin aivan muu merkki. Euro merkin voi tosin esittää turvallisesti muissakin merkistöissä entiteetillä €. Validoimalla HTML-sivun koodin esim. W3C:n validaattorilla saat tietoosi, jos sivullasi on käytetty merkkejä, jotka eivät ole osa käyttämääsi merkistöä (nämä pitää tällöin poistaa, korvata vastaavilla entiteeteillä tai vaihtaa kokonaan merkistöä).
Mutta miten sitten välitetään selaimelle tieto siitä, mitä merkistöä sivulla on käytetty? Periaatteessa www-palvelimen pitäisi huolehtia tästä. Ennen kun palvelin lähettää varsinainen HTML-sivun sisällön selaimelle, lähettää se selaimelle ns. otsaketiedot (engl. headers), joissa kerrotaan mm. mitä protokollaa käytetään (yleensä HTTP), tietoja palvelimesta sekä myös tiedon lähetettävän www-sivun merkistöstä (lähettämällä selaimelle esim. seuraavan rivin tekstiä: Content-Type: text/html; charset=utf-8). Valitettavasti läheskään kaikki palvelimet eivät tätä tietoa merkistöstä lähetä (esim. palvelin, jossa MVnet pyörii, ei sitä lähetä). Jos tietoa merkistöstä ei lähetetä, sopimuksen mukaan selain olettaa, että merkistö on ISO 8859-1. Jos sivu onkin kirjoitettu UTF-8 -merkistöllä, ollaan ongelmissa. Palvelimen lähettämiä otsaketietoja voi muokata esim. käyttämällä PHP-skriptejä tai muokkaamalla .htaccess-tiedostoa. Esimerkiksi seuraavan rivin lisääminen htaccess-tiedostoon pakottaa palvelimen lähettämään otsaketiedoissa selaimelle tiedon, että kaikki HTML-sivut ovat merkistöltään UTF-8.
AddType text/html;charset=utf-8 .html
PHP:n avulla taas voidaan määritellä yksittäisen sivun merkistö lisäämällä sivun alkuun seuraava koodipätkä (Huom! Koodipätkä pitää olla aivan sivun alussa, yhtäkään merkkiä ei saa olla ennen sitä):
<?php header('Content-type: text/html; charset=utf-8'); ?>
Edellä esitetty PHP-koodipätkä pakottaa palvelimen lähettämään selaimelle tiedon, että kyseinen sivu käyttää merkistöä UTF-8.
Oikeaoppisesti palvelimen pitäisi siis ilmoittaa sivun merkistö otsaketiedoissa. Aina ei kuitenkaan ole välttämättä mahdollista päästä vaikuttamaan näihin palvelimen lähettämiin otsaketietoihin (esim. jos PHP:tä ei voi käyttää tai htaccess-tiedostoa ei saa muokata). Tällöin, jos sivun merkistö on joku muu kuin ISO 8859-1 (joka on siis oletus, jos muuta ei kerrota), voi merkistön ilmoittaa myös itse HTML-dokumentissa meta-tägillä seuraavasti:
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
Edellä siis kerrotaan, että sivun käyttämä merkistö on UTF-8. Yhtä hyvin kirjainten utf-8 tilalle voisi laittaa jonkun muun merkistön nimen, kuten iso-8859-2. Kyseinen meta-tägi pitää sijoittaa aina head-tägien sisään ja mieluiten heti head-tägin aloitustägin jälkeen. Meta-tägiä ei ole pakko olla, jos sivun merkistö kerrotaan otsaketiedoissa. Tosin meta-tägiä on hyvä käyttää yhdessä otsaketietojen kanssa, koska näin sivun merkistö on tiedossa myös, jos kävijä tallentaa sivun omalle koneelleen (tällöinhän ei mitään otsaketietoja voida lähettää).
Näiden lisäksi sivun tekstin näkymiseen oikein vaikuttaa myös itse selaimen asetukset. Selaimen asetuksista voi yleensä määrätä itse, mitä merkistöä haluaa käyttää sivun tulkitsemiseen (esim. Internet Explorerissa: Näytä...Koodaus). Järkevin asetus on yleensä Automaattinen, jolloin selain siis päättää käytettävän merkistön otsaketiedoista tai meta-tägin perusteella. Mutta joskus jonkin sivun merkistö on saatettu ilmoittaa väärin ja ainoa vaihtoehto on määrätä selaimen asetuksista oikea merkistö itse, jos haluaa sivun näkyvän oikein. Tällöin tosin asetus voi jäädä huomaamatta päälle, jolloin taasen muilla sivuilla saatetaan käytetään väärää merkistöä.
Selaimet tulkitsevat sivun merkistön seuraavasti (tärkeysjärjestyksessä korkeimmasta matalimpaan):
- Selaimen asetuksissa määrätty merkistö (jos joku muu kuin automaattinen)
- Otsaketiedoissa kerrottu merkistö
- Meta-tägissä kerrottu merkistö (jos otsaketiedoissa ei kerrottu merkistöä)
- Jos mitään näistä ei ole kerrottu, voi selain yrittää päätellä merkistön itse (tämä ei tosin aina onnistu täysin oikein)
Eli itse selaimessa määritetty käytettävä merkistö ohittaa kaikki muut (tällöin selain viis veisaa esim. otsaketiedoissa kerrotusta merkistöstä). Jos ääkköset näkyvät oudosti, on siis syytä tarkistaa ensin oman selaimen asetukset. Kannattaa myös huomata, että jos HTML-sivun merkistö on kerrottu otsaketiedoissa, ei selain välitä enää siitä, mitä merkistöksi on kerrottu meta-tägissä. Siksi sivu voikin näkyä väärin, jos se on tallennettu merkistöllä UTF-8, joka on kerrottu myös meta-tägissä, mutta palvelin lähettääkin otsaketiedoissa ilmoituksen, että sivu käyttää merkistöä ISO 8859-1.
Yleensä, jos HTML-sivua muokkaa Windows -käyttöjärjestelmissä, tallennetaan tiedostot merkistöllä Windows-1252. Koska Windows-1252 on laajennus ISO 8859-1:een, ei HTML-sivulle yleensä tarvitse lisätä edellä kerrottua meta-tägiä eikä palvelimen otsaketietoihin tarvitse kajota (koska oletuksena käytetään merkistöä ISO 8859-1, joka on lähes sama kuin Windows-1252). Tässä pitää kuitenkin ottaa huomioon, että esim. euro-merkkiä ei saa käyttää, koska se ei ole osa ISO 8859-1:stä, vaikka se Windows-1252:stä löytyykin. ISO 8859-1 ja Windows-1252 -merkistöjen erot löytyvät esim. englanninkieliseltä sivulta Differences between ANSI, ISO 8859-1 and MacRoman character sets.
Mitä merkistöä sitten kannattaa www-sivuilla käyttää? Itse suosittelisin käyttämään joko merkistöä ISO 8859-1 tai UTF-8. Nämä ovat kaikista yleisimmät. Windowsissa aloittelija pääsee ehkä helpoimmalla, jos käyttää merkistöä ISO 8859-1, koska Windowsissa käytetty Windows-1252 on hyvin lähellä kyseistä merkistöä ja se soveltuu suomen kieleen melko hyvin. Selaimelle ei yleensä kannata kertoa, että sivulla käytetään merkistöä Windows-1252 eikä sivulla myöskään kannata käyttää Windows-1252:n tuomia lisämerkkejä (kuten merkit €, ‰, — ja š), koska tämä voi aiheuttaa ongelmia muualla kuin Windows-ympäristössä. Järkevintä on siis pysytellä ISO 8859-1:n tarjoamissa merkeissä ja kirjoittaa muut erikoismerkit entiteeteillä.
UTF-8 taas on kyllä tulevaisuutta, mutta sen kanssa eteen saattaa tulla aloittelijalle joitain ongelmia editoidessa tiedostoja Windows-ympäristössä, kuten tiedoston alussa oleva ns. BOM-merkki (Byte-Order Mark), jota ei HTML-sivuissa saisi olla, mutta Windowsissa tämä yleensä tiedostoon laitetaan. Jos tekee www-sivuja Linux-ympäristössä, helpoimmalla pääsee yleensä käyttämällä UTF-8-merkistöä, koska useimmat Linux-käyttöjärjestelmät tallentavat tiedostot oletuksena UTF-8 -merkistöllä. Lisäksi, jos www-sivussa käytetään paljon erikoismerkkejä tai kirjoitetaan jotain kieltä, jossa on muitakin merkkejä kuin perusaakkosia (esim. venäjän kyrilliset merkit), on suositeltavaa käyttää UTF-8-merkistöä. Periaatteessa tiedostoon, joka tallennetaan UTF-8-merkistöllä, voi lätkiä mitä merkkejä haluaa (vaikka japania tai kiinaa), jos vaan näitä merkkejä voi kirjoittaa (suomalaisella näppäimistöllä tämä on ehkä vähän hankalaa). Tämä ei olisi mitenkään mahdollista ISO 8859-1 -merkistöllä, joka pystyy esittämään vain 256 merkkiä. Windowsissa voi tallentaa tekstitiedostoja UTF-8-merkistöllä käyttämällä esim. tekstieditorina ohjelmaa nimeltä Notepad++. Sivulta UTF-8 SAMPLER taas voi katsoa, millaiselta näyttää UTF-8 -merkistöön tallennettu www-sivu, jossa on paljon erikoismerkkejä (japania, kiinaa, kreikkaa, venäjää jne.). Kaikki sivun merkit eivät välttämättä näy oikein, jos koneellasi ei ole tarvittavia fontteja.
Seuraava sivu (Kotisivujen toteutus) >> << Edellinen sivu (Miksi kotisivut?)